I’m writing this post in WordPress, something I never thought I’d be doing. I personally try to avoid such frameworks.
Why? It’s simple. Most of the work I do is custom coding; developing applications involving logging in and accessing and manipulating data that businesses and their clients rely on. That’s not a good fit for a WordPress site. Hammering such work into such a framework would be painful to do and even worse to maintain.
I don’t use WordPress. I don’t use CakePHP. I don’t use the ZEND framework. Joomla. Magento. Countless others. (Yes, I’m throwing frameworks, shopping carts and CMSes all in the same box – sue me)
I don’t use frameworks, and most of my work is (gasp, get ready) – procedural code. Horror! Not even Object Oriented. Pure insanity.
I write my code from scratch, and it’s procedural. And it runs very, very fast.
Let’s take a look at a few facts. Writing a class in PHP, and defining a method in that class, and then calling that method to execute some block of code runs 33% slower than simply writing the code in a function and calling it directly. 33%. Sounds almost trivial, right?
Let’s scale that up. Let’s say you’ve got a whole library of classes you’ve developed over the years, and pretty much everything you do is using an object of one type or another. To load a single page you might have fifty or more methods that get called and executed. That 33% could mean the difference between a three second page load and a two second page load. Okay, still no big deal.
But now let’s add in one of these pre-packaged frameworks. Wordpress. Magento. Drupal. Choose your poison.
Now, your essential bit of code gets wrapped inside a larger framework. This framework is responsible for drawing the page that the visitor to your site eventually sees. But the frameworks also offer something else. They offer a promise to someone with no coding experience, that by using this framework, they’ll be able to easily create and maintain their own website, without having to hire someone. Sounds nice. (More about that in another post)
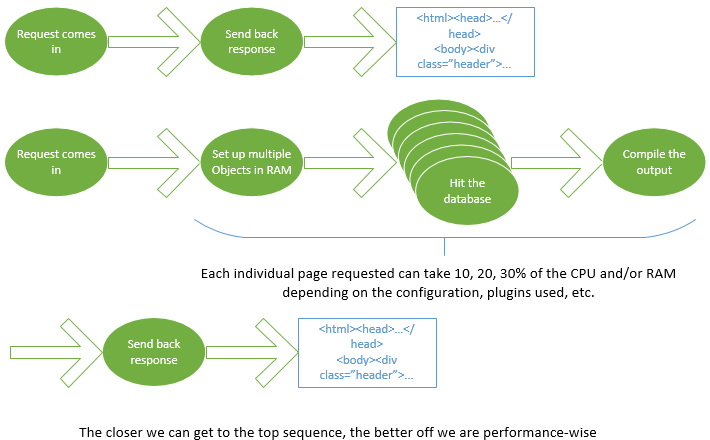
How do they offer this convenience? Easy. Everything goes in the database. The user uploads an image to appear on every page. The file gets stored in the filesystem, and a reference to its name and location gets stored in the database. The user gives a name to the site, and that gets stored in the database. The user defines what the items on the menu are, and each one gets a corresponding entry in the database. So far, so good.
But now, when it comes time to draw the page and show it to the visitor, the framework has to go to – you guessed it: the database. Over and over again. Depending on the complexity of the site, and the number of plugins used, a WordPress (Magento, Joomla….) site can hit the database three hundred (or more) times just to figure out what the page is meant to look like, what the content it’s serving is, what the footer contains, etc.
As far as performance goes, retrieving a value from a database stored on a platter drive (still the predominant technology, although SSD drives are becoming more common on servers) ONE TIME can consume fifty million CPU cycles. Multiply that by possibly three hundred database calls. Keep in mind this is just to draw ONE page, one time, for one visitor. Now say you have a somewhat popular site and fifty or a hundred people want to view that page in the same second. Wow. Suddenly your site is brought to a crawl.
Instead of serving HTML, it’s now compiling HTML with the help of a (slow) database.
I’m sorry, but I find this insane. Remember, no matter the underlying technology used, what goes to the browser is still HTML. You can use WordPress, Joomla, Magento, CakePHP, Zencart, whatever, and at the end of the day, what it’s going to send to your visitor is HTML. (Yes, yes, and CSS, Javascript, images, etc. But all those get called by the html to begin with)
Listen, the header image of your site didn’t change in the last hour, and in all probability, it won’t change in the next two weeks. So why is WordPress hitting your database to determine what your header is? Because it has to. Because it’s a one-size-fits-all-and-you-can-maintain-your-own-website! framework. Same for the menu. Instead of just firing the menu back as part of the page, it’s compiling the menu. The same menu it served up one second ago to a different visitor, it’s now busy re-computing, to come up with the same answer it had one second ago, again. And again. And again.
And it’s Object Oriented. Yay! Whoo hoo.
I’ve seen WordPress sites (hosted on fast equipment) take ten seconds to load on a fast connection. And Magento sites take twenty+ seconds to load a page.
The worst instance of horrible performance I’ve ever seen was a ZEND framework site that literally takes upward of forty seconds to load a single page. Sometimes over a minute. Time enough for a pee break between the click and the page load.
I had the opportunity to look at the codebase that was responsible for this. It was beautiful, well-formed, best-practices-heavily-adhered-to, MVC nightmare. To trace how a page came to be born you had to weave your way through a multitude of short bits of code. The guy I was doing this for had been tasked with the job of changing the styling. Just the look and feel of parts of it. Lord have mercy on his soul. This poor man (not a coder, but a HTML/CSS guy) had to go through endless small little files to find where a certain element had came from just to piece together how this go-make-some-coffee-while-your-page-loads monster came to be so he could change it. Ugh.
Call me crazy, but I think there’s a better way. I understand the idea behind an MVC framework. Honest, I do. I understand the principles of Object Oriented software. Really, I swear I get it. I even use it in it’s proper place.
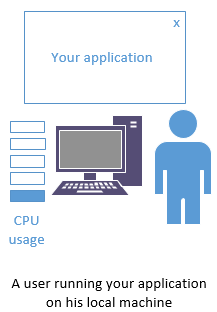 When I do .NET development it’s all Object Oriented. That’s the way it’s done in that environment. But consider the use case. An application that runs on a user’s own computer is a single copy of the entire framework and everything that’s needed on the user’s own hardware. This is an important point. If your application takes up 5-10% of the resources on the computer (not too hard to do by the way) that’s fine, because the CPU isn’t busy serving twenty other similar requests in the same second.
When I do .NET development it’s all Object Oriented. That’s the way it’s done in that environment. But consider the use case. An application that runs on a user’s own computer is a single copy of the entire framework and everything that’s needed on the user’s own hardware. This is an important point. If your application takes up 5-10% of the resources on the computer (not too hard to do by the way) that’s fine, because the CPU isn’t busy serving twenty other similar requests in the same second.
That’s your application running on a personal computer. Even if you’re tying up 10% of the CPU cycles and 20% of the RAM, so what? Everyone’s happy. Use Object Oriented code. In fact you kind of have to. Go to town with MVC frameworks. It’s not going to make a big performance difference.
But doing that on a server is, in my humble opinion, MADNESS. You’re dealing with a SERVER. It’s meant to serve files, data, images, whatever. And it’s meant to do it in quantity. Over and over.
To give your server the additional job of hitting the database to find out what the page is meant to look like, calculating and compiling it all, and, to compound the felony, to do it all through OO and MVC frameworks, fuck, you’re just asking for trouble, aren’t you?
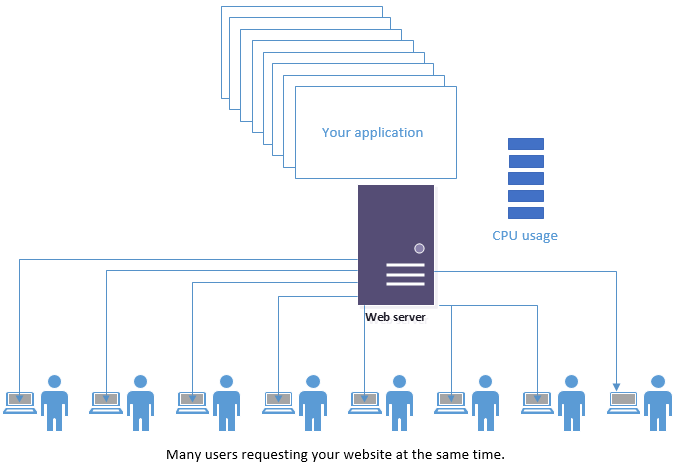
Let’s back up. Let’s look at real-world facts. Almost all sites are hosted on shared resources. By resources I mean the hardware the site runs on – the CPU, RAM, hard disk, etc. The few sites that actually command their own hardware are rare. You’re most likely going to be on a server with other websites. Whether that means you’re on a box with other clients of the guy/company who put your site together, or if you go with hosting from Godaddy, Bluehost, Hostgator, etc. (all terrible options, by the way), you’re going to end up with other sites competing for the resources of the server. And I dare say that most of those sites also run on some you-can-build-and-maintain-your-own-site framework too. I feel bad for you. Really.
When a visitor comes to your site, the shit hits the fan. Guess what, your visitor has to wait. Why? Because the server you’re on is busy with the last thirty requests that came in within the last second. Probably not for your site, but for one of your roommates (most hosting companies throw a lot of sites on one box). The CPU you’re depending on is busy calculating what the menu is to look like for a site. Over and over. Eventually it will get to your visitor’s request. Eventually.
Maybe you’re lucky. Maybe your visitor only has to wait a second or two before it starts calculating what your menu looks like this exact second, which is, by the way, exactly what your menu looked like three seconds ago when serving another request for your site.
I could go on, but you probably already get the point. Why do this to begin with? Why not man up, put your big boy pants on and code the HTML that is to be served to the visitor directly? At the end of the day, that’s what the request will result in.
HTML. Hyper Text Markup Language. That’s what’s going to the browser no matter what you put in between the request and the response.
Coming up with the same answer, over and over again
Dynamic (not always the same) pages require some additional technology, like PHP to decide what the different parts are going to be. But why lean on the slowest technologies you can find (database calls) to determine what’s already known? Fuck, you haven’t changed your header in a month. Why is your server, today, going to the database again to draw the same damn menu? I find this arrangement stupid.
True, the days when you could just code pages in straight HTML are long, long gone. But let’s be reasonable. We don’t have to hit the database to draw the same header, same footer, same menu every time. Dynamic sites require some processing, no doubt. But extending that dynamic-ness into every single corner of your website? That’s taking a good thing and killing yourself with it. Your body can’t live without water, but did you know that you could die if you drank three gallons in the next ten minutes?
If you want a faster website, you’re going to have to grow up. You can’t run to mama (WordPress, Joomla…) to save you. True, there are caching options, and other performance upgrades that can help speed up a sluggish site or server. But we need to stop making servers hit databases for answers that don’t have to be stored in databases.
And Object Orientation, MVC, frameworks, these are all good technologies. But they were designed for a different use. They were designed for software that runs on a client’s OWN MACHINE. Photoshop is going to run one instance on your computer. Not twenty instances per second. I personally don’t feel that OO or MVC have any place being run on a server. At all. The resources the Objects and frameworks tie up are too precious on a server. Other than bandwidth (and all the stupid bloated content many sites serve), this is why you have to wait ten seconds for somes page to load on your phone.
I don’t know about you, but personally, if I’m waiting ten seconds for a page to load, I’m gone. Doesn’t matter how interesting the link looked, I’m not waiting that long for the content. Sorry; I can’t be bothered to wait.
The great crime, mixing presentation and logic
The way I do things might look pretty weird to other coders. They might think my coding was ancient, out of date, and that it belonged on the Antiques Roadshow. But my code runs fast. By not using OO (except in libraries where I have to), by not using an MVC framework on the server, I save CPU cycles. Lots of them.
The common elements of a page are in a header file containing straight HTML. Same with the footer. Gasp – straight HTML? Yep. That means I can’t rely on a framework. Oh well. At least the server isn’t doing any calculating. Guess what, if the header has to change I’m the one who has to do it. Time for the big boy pants.
The parts that are truly dynamic are written in PHP. And may the gods of ‘best practices’ show me mercy – they’re written without the benefits of Object Orientation. The horror.
And, even worse (I’ll probably be burned at the stake) I’ll mix HTML in with my PHP. Heck, I’ll even have my PHP determine which lines of Javascript get sent to the browser. Imagine! PHP writing Javascript? Insanity. But I figure why send the browser Javascript that isn’t needed for that particular page? Strange concept, I know.
But yet, with all the ‘best practices’ telling you the necessities of keeping the presentation and the logic separate, I still can find code like this (not my code), embedded 1,200 lines deep inside a ZEND framework CONTROLLER file (shouldn’t have any VIEW parts in it, right?):
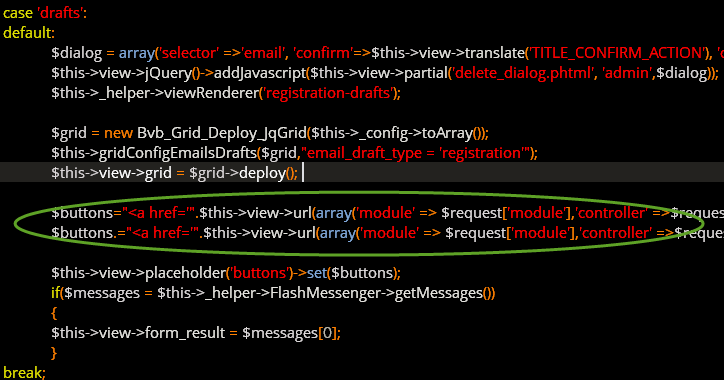
I’m sorry, but did I miss something? I thought that the MVC framework was supposed to keep the HTML (view) completely separate from the logic (controller)? So here we are, both me (the heretic) and the ‘best-practices’ coders sleeping in the same bed – presentation and logic in the same place. How would you like to maintain an MVC project where a certain anchor tag is 1,200 lines down inside an MVC Controller file? And the rest of the page was composed from thirty different other files?
Not me. I find it simpler and more effective to just write straight HTML where I need to and put the dynamic logic right where it’s needed. It’s light on it’s feet, it’s not too difficult to maintain, and it runs fast.
The results
The proof of this is easily seen by taking a look at ‘top’ (the linux tool to show you which processes are using what amount of resources, at one second intervals). This is my code running on a server, servicing four requests in one particular second:
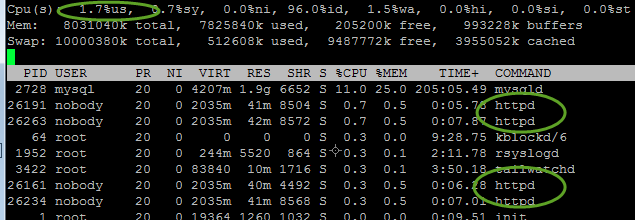
As you can see, the cpu is completely yawning along at 1.7% usage. Each individual http request is taking between 0.3 and 0.7 percent of the cpu. And let me assure you these aren’t static pages. They’re fully dynamic and serving custom content to each user based on where they are in the app.
Now, for comparison, here’s an older version of this same app written in Java (not my code), also servicing four requests in a given second:
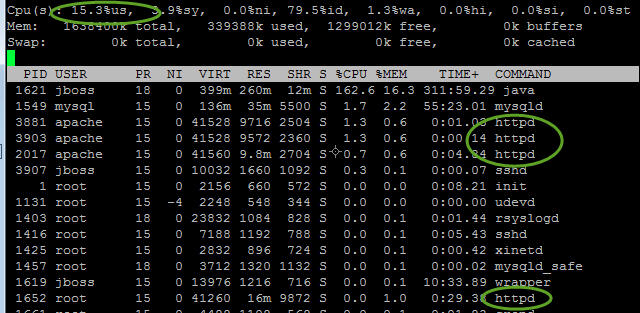
As you can see, Java is taking up 162.6% of one cpu, just to service these four requests. Java is of course the ultimate in Object Oriented frameworks. Which server do you think is going to have an easier time when twenty requests come in one second?
Here’s another application, also written in Java. This one is chewing up 88% of four CPUs to service five incoming requests. Five requests! What happens when there’s seven? You guessed it; serious lag.
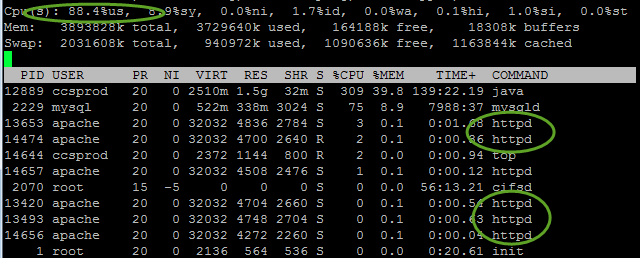
To repeat, I don’t believe Object Oriented code belongs on a server. This is why.
A shift in paradigm to the rescue
Okay, you’ve been taught you haaaave to have an MVC framework. Great. Move it to the client side, such as has been happening recently. It’s actually a pretty good move.
The move to client-side frameworks is completely correct. Packing all the CPU-intensive OO and MVC code into javascript and having the user’s machine do all the work is the right way to go. JQuery, Angular, and other frameworks built off of Javascript takes the burden of compiling the page off of the server, and puts it onto the client computer. This leaves the server doing very little calculating and lets it just serve out the files – let the client’s machine do the work of figuring out what the page is supposed to look like and contain. That’s a beautiful arrangement and I’m happy to see the moves in this direction. It won’t save you from your other crimes of sending out 2MB sized images – your bloated content is a different topic, but at least you’re not overloading your server by making it recalculate your navigation ten million times a day.
But for god’s sake – please let’s forget about server side frameworks. The future of the web belongs on the client side; let’s get there sooner rather than later.